learn-kubernetes
花一个月时间学习 Kubernetes
第八章 使用 StatefulSets 和 Jobs 运行数据量大的应用
“数据量大” 不是一个很科学的术语,但本章是关于运行一个应用程序类,它不仅是有状态的,而且还要求它如何使用状态。数据库就是此类的一个例子。它们需要跨多个实例运行以实现高可用性,每个实例都需要一个本地数据存储以实现快速访问,而且这些独立的数据存储需要保持同步。数据有其自身的可用性要求,您需要定期运行备份以防止终端故障或损坏。其他数据密集型应用程序,如消息队列和分布式缓存,也有类似的需求。
你可以在 Kubernetes 中运行这些类型的应用程序,但你需要围绕一个固有的冲突进行设计:Kubernetes 是一个动态环境,而数据量大的应用程序通常希望在一个稳定的环境中运行。群集应用程序希望在已知的网络地址中找到对等点,但在ReplicaSet 中不能很好地工作,而备份作业希望从磁盘驱动器中读取数据,因此在 persistentvolumecclaims 中不能很好地工作。如果你的应用程序有严格的数据要求,你需要对它进行不同的建模,我们将在本章中介绍一些更高级的控制器:StatefulSets, Jobs 和 CronJobs。
8.1 Kubernetes 如何用 StatefulSets 建模稳定性
StatefulSet 是一个具有可预测管理特性的 Pod 控制器:它允许您在一个稳定的框架内大规模运行应用程序。当您部署 ReplicaSet 时,它会使用随机名称创建 Pod,这些名称不能通过域名系统(DNS)单独寻址,并且它会并行启动它们。当你部署一个 StatefulSet 时,它会创建具有可预测名称的 Pod,这些 Pod 可以通过 DNS 单独访问,并按顺序启动它们;第一个 Pod 需要启动并运行在第二个 Pod 创建之前。
集群应用程序是 StatefulSet的一个很好的候选。它们通常设计有一个主实例和一个或多个辅助实例,这使它们具有高可用性。您可能能够扩展辅助服务器,但它们都需要到达主服务器,然后使用主服务器同步它们自己的数据。你不能用Deployment 来建模,因为在 ReplicaSet 中,没有办法将单个 Pod 识别为主节点,所以你最终会遇到多个主节点或零主节点的奇怪且不可预测的情况。
图 8.1 显示了一个例子,它可以用来运行我们在前几章中为待办事项列表应用程序使用的 Postgres 数据库,但是它使用了一个 StatefulSet 来实现复制数据和高可用性。
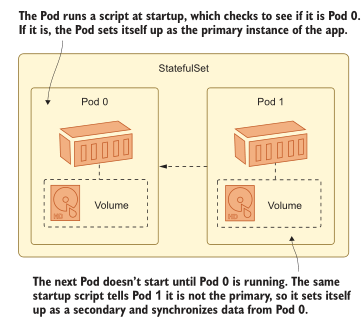
为此的设置相当复杂,我们将分阶段花几个部分来完成,以便您了解工作中的 StatefulSet 的所有部分是如何组合在一起的。这种模式不仅对数据库有用——许多旧的应用程序是为静态运行时环境设计的,并且对稳定性做出了假设,但这些假设在Kubernetes 中并不成立。StatfulSets 允许你对这种稳定性建模,如果你的目标是将你现有的应用程序转移到 Kubernetes,那么它们可能是你在这一旅程的早期使用的东西。
让我们从一个简单的 StatefulSet 开始,它展示了基础知识。清单 8.1 显示了 StatefulSets 具有与其他 Pod 控制器几乎相同的 spec,除了它们还需要包含服务的名称。
清单 8.1 todo-db.yaml, 一个简单的 StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: todo-db
spec:
selector: # StatefulSets 使用了相同的选择器机制
matchLabels:
app: todo-db
serviceName: todo-db # StatefulSets 必须关联 Service.
replicas: 2
template:
# pod spec...
当您部署这个 YAML 文件时,您将得到一个运行两个 Postgres pod 的 StatefulSet,但不要太兴奋——它们只是两个单独的数据库服务器,恰好由同一个控制器管理。要使两个 pod 成为一个复制的数据库集群,还需要做更多的工作,我们将在接下来的几节中实现这一点。
现在就试试 部署清单 8.1 中的 StatefulSet,看看它创建的 pod 与 ReplicaSet 管理的 pod 有什么不同
# 切换到本章的源码目录:
cd ch08
# 部署 StatefulSet, Service, 以及用于 Postgres 密码的 Secret:
kubectl apply -f todo-list/db/
# 检查 StatefulSet:
kubectl get statefulset todo-db
# 检查 Pods:
kubectl get pods -l app=todo-db
# 查看 Pod 0 的主机名:
kubectl exec pod/todo-db-0 -- hostname
# 检查 Pod 1 的日志:
kubectl logs todo-db-1 --tail 1
从图 8.2 中可以看到,StatefulSet 的工作方式与 ReplicaSet 或 DaemonSet 非常不同。Pod 有一个可预测的名称,即 StatefulSet 名称后面跟着 Pod 的索引,因此您可以使用它们的名称来管理 Pod,而不必使用标签选择器。
Pod 仍然由控制器管理,但以一种比 ReplicaSet 更可预测的方式。Pod 是按照从 0 到 n 的顺序创建的;如果您缩小集合,控制器将以相反的顺序删除它们,从 n 开始向下。如果删除 Pod,控制器将创建一个替换。它的名称和配置将与原来的相同,但它将是一个新的Pod。

现在就试试 删除Pod 0 的 StatefulSet,并看到 Pod 0 再次返回
# 检查 Pod 0 的内部 id:
kubectl get pod todo-db-0 -o jsonpath='{.metadata.uid}'
# 删除 Pod:
kubectl delete pod todo-db-0
# 检查 Pods:
kubectl get pods -l app=todo-db
# 检查新的 Pod 完全是全新的:
kubectl get pod todo-db-0 -o jsonpath='{.metadata.uid}'
你可以在图 8.3 中看到,StatefulSet 为 app 提供了一个稳定的环境。Pod 0 被替换为一个相同的Pod 0,但这不会触发一个全新的设置; 原来的 Pod 1仍然存在。仅在创建和扩展时应用顺序,不用于替换缺失的 Pod。
{kind=link}
StatefulSet 只是对稳定环境建模的第一部分。您可以获取每个 Pod 的 DNS 名称,将 StatefulSet 链接到一个服务,这意味着您可以配置 Pod,通过使用已知地址上的其他副本来初始化它们自己。
8.2 在 StatefulSets 中使用 init 容器引导 Pod
Kubernetes API 从其他对象中组合对象: 在 StatefulSet 定义中的 Pod 模板与在 Deployment 模板和 裸Pod定义中使用的对象类型相同。这意味着 Pod 的所有功能都可以用于 StatefulSets,尽管 Pod 本身是以不同的方式管理的。我们在第7章学习了 init 容器,对于集群应用程序中经常需要的复杂初始化步骤,它们是一个完美的工具。
清单 8.2 显示了用于更新 Postgres 部署的第一个init容器。这个Pod Spec 中的多个 init 容器是按顺序运行的,而且由于 Pod 也是按顺序启动的,所以可以保证Pod 1 中的第一个init容器在 Pod 0 完全初始化并准备就绪之前不会运行。
清单8.2 todo-db.yaml,复制的 Postgres 设置初始化
initContainers:
- name: wait-service
image: kiamol/ch03-sleep
envFrom: # env 文件用于在容器之间共享
- configMapRef:
name: todo-db-env
command: ['/scripts/wait-service.sh']
volumeMounts:
- name: scripts # 卷从 ConfigMap 装载脚本
mountPath: "/scripts"
在这个 init 容器中运行的脚本有两个功能: 如果它在 Pod 0 中运行,它只是打印一个日志来确认这是数据库主容器,然后容器退出;如果它在任何其他 Pod 中运行,它会对主 Pod 进行 DNS 查找调用,以确保在继续之前可以访问它。下一个init 容器将启动复制进程,因此这个容器将确保一切就绪。
本例中的具体步骤是特定于 Postgres 的,但许多集群和复制应用程序的模式是相同的——mysql、Elasticsearch、RabbitMQ和nat都有大致相似的需求。图 8.4 显示了如何在 StatefulSet 中使用init容器对该模式建模。
{kind=link}
您可以通过在 spec 中标识服务来为 StatefulSet 中的各个 Pods 定义 DNS 名称,但它需要是 headless Service 的特殊配置。清单 8.3 显示了如何在没有 ClusterIP 地址的情况下配置数据库服务,并为 Pods 配置一个选择器。
清单8.3 todo-db-service.yaml,一个 StatefulSet 的 headless Service
apiVersion: v1
kind: Service
metadata:
name: todo-db
spec:
selector:
app: todo-db # Pod 选择器与 StatefulSet 相匹配.
clusterIP: None # Service 将不会拥有自己的 Ip 地址.
ports:
# ports follow
没有 ClusterIP 的 Service 仍然可以作为集群中的 DNS 条目,但它不会为该服务使用固定的 IP 地址。没有由网络层路由到真实目的地的虚拟 IP。相反,服务的 DNS 条目为 StatefulSet 中的每个 Pod 返回一个 IP 地址,并且每个 Pod 还获得自己的 DNS 条目。
现在就试试 我们已经部署了 headless Service,所以我们可以使用 sleep Deployment 来查询 StatefulSet 的 DNS,看看它与典型的 ClusterIP 服务相比如何
# 查看 Service 明细:
kubectl get svc todo-db
# 运行一个 sleep Pod 用于网络查找:
kubectl apply -f sleep/sleep.yaml
# 运行 Service 名称的 DNS 查询:
kubectl exec deploy/sleep -- sh -c 'nslookup todo-db | grep "^[^*]"'
# 运行 Pod 0 的 DNS 查找:
kubectl exec deploy/sleep -- sh -c 'nslookup todo-db-0.todo-
db.default.svc.cluster.local | grep "^[^*]"'
在本练习中,您将看到 Service 的 DNS 查找返回两个 IP 地址,它们是 Pod 内部IP。Pods 本身有自己的格式为 pod-name 的 DNS 条目。带有通常集群域后缀的服务名称。图 8.5 显示了我的输出。
 </center>图 8.5 StatefulSets 为每个 Pod 提供自己的 DNS 条目,因此它们是单独可寻址的</center>
</center>图 8.5 StatefulSets 为每个 Pod 提供自己的 DNS 条目,因此它们是单独可寻址的</center>
可预测的启动顺序和单独可寻址的 Pod 是在 StatefulSet 中初始化集群应用的基础。具体细节在不同的应用程序之间会有很大的不同,但从广义上讲,Pod 的启动逻辑将是这样的: 如果我是Pod 0,那么我是主设备,所以我做所有的主设备设置工作;否则,我是一个辅助,所以我将给主服务器一些时间来设置,检查一切都正常工作,然后使用 Pod 0 地址进行同步。
Postgres 的实际设置相当复杂,所以我在这里略过。它使用 ConfigMaps 中的脚本和 init 容器来设置主服务器和备用服务器。到目前为止,我在 StatefulSet 的 spec 中使用了书中介绍的各种技术,值得探索,但脚本的细节都是特定于Postgres 的。
现在就试试 更新数据库,使其成为一个复制的设置。ConfigMaps 中有配置文件和启动脚本,并且更新 StatefulSet 以在 init 容器中使用它们
# 部署副本方式的 StatefulSet 应用设置:
kubectl apply -f todo-list/db/replicated/
# 等待 Pods 就绪
kubectl wait --for=condition=Ready pod -l app=todo-db
# 检查 Pod 0日志—主节点:
kubectl logs todo-db-0 --tail 1
# 以及 Pod 1—从节点:
kubectl logs todo-db-1 --tail 2
Postgres 使用主-被动模型进行复制,因此主服务器用于数据库读写,从服务器从主服务器同步数据,可供客户端使用,但仅用于读访问。图 8.6 显示了 init 容器如何识别每个 Pod 的角色并初始化它们。

像这样初始化复制应用的大部分复杂性都是围绕工作流建模,这是特定于应用的。这里的 init 容器脚本使用 pg_isready 工具来验证主应用是否准备好接收连接,并使用 pb_basebackup 工具来启动复制。这些实现细节从管理系统的操作员那里抽象出来。他们可以通过扩大 StatefulSet 来添加更多的副本,就像使用任何其他复制控制器一样。
现在就试试 扩大数据库以添加另一个副本,并确认新的 Pod 也作为备用启动
# 添加另一个副本:
kubectl scale --replicas=3 statefulset/todo-db
# 等待 Pod 2 就绪
kubectl wait --for=condition=Ready pod -l app=todo-db
# 检查新 Pod 是否设置为另一个备用:
kubectl logs todo-db-2 --tail 2
我不认为这是一个企业级的产品设置,但这是一个很好的起点,真正的 Postgres 专家可以接管它。现在,您有了一个功能良好的复制 Postgres 数据库集群,其中有一个主数据库和两个备用数据库——Postgres称它们为备用数据库。如图8.7所示,所有备用服务器都以相同的方式启动,从主服务器同步数据,客户端都可以使用它们进行只读访问。

这里遗漏了一个明显的部分——数据的实际存储。我们所拥有的设置并不是真正可用的,因为它没有任何用于存储的卷,因此每个数据库容器都在自己的可写层中写入数据,而不是在持久卷中写入数据。StatefulSets 有一种定义卷需求的简洁方法:您可以在 spec 中包含一组持久卷声明(PVC)模板。
8.3 使用卷声明模板请求存储
卷是标准 Pod Spec 的一部分,您可以为 StatefulSet 将 ConfigMaps 和 Secrets 加载到 Pod 中。你甚至可以包含一个 PVC 并将其挂载到应用程序容器中,但这将为你提供在所有 Pod之间共享的卷。在只读配置设置中,您希望每个 Pod 都有相同的数据,但如果您为数据存储安装了标准 PVC,那么每个 Pod 都将尝试写入相同的卷。
您实际上希望每个 Pod 都有自己的 PVC, Kubernetes 在 Spec 中为 StatefulSets 提供了 volumeClaimTemplates 字段,它可以包括存储类以及容量和访问模式需求。当您部署带有 volume claim templates 的 StatefulSet 时,它为每个Pod 创建一个 PVC,并且它们是链接的,因此如果 Pod 0 被替换,新的 Pod 0 将附加到前一个Pod 0 使用的 PVC 上。
清单8.4 sleep-with-pvc.yaml,一个带有 volume claim templates 的 StatefulSet
spec:
selector:
# pod selector...
serviceName:
# headless service name...
replicas: 2
template:
# pod template...
volumeClaimTemplates:
- metadata:
name: data # 卷挂载到 Pod 中的名字
spec: # 这个是标准的 PVC spec
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Mi
在将 StatfulSets 中的 volume claim templates 添加为数据库集群的存储层之前,我们将使用这个练习来了解它们在一个简单的环境中是如何工作的。
现在就试试 部署清单 8.4 中的 StatefulSet,并探索它创建的 Pvc
# 部署带有 volume claim templates 的 StatefulSet:
kubectl apply -f sleep/sleep-with-pvc.yaml
# 检查创建的 PVC:
kubectl get pvc
# 在 Pod 0 挂载的 PVC 中写入一些数据:
kubectl exec sleep-with-pvc-0 -- sh -c 'echo Pod 0 > /data/pod.txt'
# 确认 Pod 0 可以读取到数据:
kubectl exec sleep-with-pvc-0 -- cat /data/pod.txt
# 确认 Pod 1 读取不到—将会失败:
kubectl exec sleep-with-pvc-1 -- cat /data/pod.txt
您将看到集合中的每个 Pod 都得到一个动态创建的 PVC,而 PVC 又使用默认存储类(或者是请求的存储类,如果我在 spec 中包含了一个)创建了一个PersistentVolume。PVC 都具有相同的配置,并且它们使用与 StatfulSet中的 Pod 相同的稳定方法:它们具有可预测的名称,并且如图8.8所示,每个 Pod 都有自己的PVC,为副本提供独立的存储。

Pod 和它的 PVC 之间的链接在替换 Pods 时得到维护,这才是真正赋予 StatefulSets 运行数据量大的应用程序的能力。当你推出一个更新到你的应用程序,新的 Pod 0 将附加到从以前的 Pod 0 的 PVC,新的应用程序容器将访问与替换的应用程序容器完全相同的状态。
现在就试试 通过移除0号 Pod 触发 Pod 更换。它将被替换为另一个Pod 0,连接到相同的PVC
# 删除 Pod:
kubectl delete pod sleep-with-pvc-0
# 检查替换的 Pod 已创建:
kubectl get pods -l app=sleep-with-pvc
# 检查新的 Pod 0 可以看到旧数据:
kubectl exec sleep-with-pvc-0 -- cat /data/pod.txt
这个简单的例子说明了这一点——在图 8.9 中可以看到,新的 Pod 0 可以访问原始 Pod 中的所有数据。在生产集群中,您可以指定一个存储类,该存储类使用任何节点都可以访问的卷类型,因此替换 Pods 可以在任何节点上运行,而应用程序容器仍然可以挂载 PVC。

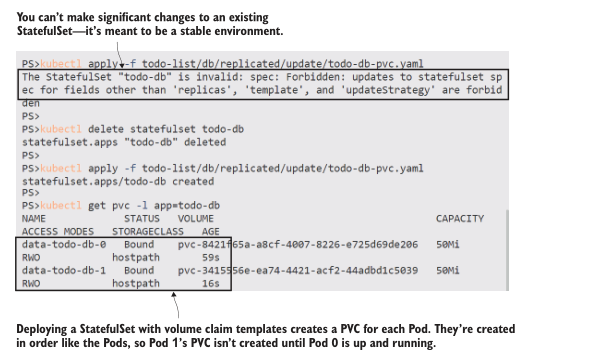
Volume claim templates 是我们需要添加到 Postgres 部署中的最后一部分,以建模完全可靠的数据库。StatefulSet 旨在为您的应用程序提供一个稳定的环境,因此当涉及到更新时,它们不如其他控制器灵活—您不能更新现有的 StatefulSet 并进行根本性的更改,例如添加卷声明。您需要确保您的设计满足 StatefulSet的应用程序需求,因为在大的更改期间很难保持服务水平。
现在就试试 我们将更新 Postgres 部署,但首先我们需要删除现有的StatefulSet
# 对 volume claim templates 应用更新—这将失败:
kubectl apply -f todo-list/db/replicated/update/todo-db-pvc.yaml
# 删除 StatefulSet:
kubectl delete statefulset todo-db
# 创建一个包含 volume claims 的新的 StatefulSet:
kubectl apply -f todo-list/db/replicated/update/todo-db-pvc.yaml
# 检查 volume claims:
kubectl get pvc -l app=todo-db
当您运行这个练习时,您应该清楚地看到 StatefulSet 如何保持顺序,并在启动下一个 Pod 之前等待每个 Pod 运行。PVC 也是按顺序为每个 Pod 创建的,从我的输出中可以看到,如图8.10所示。
感觉我们在 StatefulSets 上花了很长时间,但这是一个你应该很好地理解的主题,所以当有人要求你将他们的数据库移动到 Kubernetes(他们会的)时,你不会感到惊讶。StatefulSets 具有相当大的复杂性,您将在大多数情况下避免使用它们。但是如果你想把现有的应用程序迁移到 Kubernetes上,StatefulSets可以让你在同一个平台上运行所有的东西,或者不得不保留几个 vm 来运行一两个应用程序。
我们将通过一个练习来结束本节,以展示集群数据库的强大功能。Postgres 辅助服务器从主服务器复制所有数据,客户端可以使用它进行只读访问。如果我们的待办事项列表应用程序出现了严重的生产问题,导致它丢失数据,我们可以选择切换到只读模式,并在调查问题时使用次要模式。这样可以让应用程序以最小的功能安全地运行,这绝对比让它脱机要好。
现在就试试 运行待办事项 web 应用程序并输入一些项目。在默认配置中,它连接到 statfulset 的 Pod 0 中的Postgres主节点。然后我们将切换应用程序配置,将其设置为只读模式。这使得它连接到 Pod 1 中的只读Postgres备用,后者已经从 Pod 0复制了所有数据
# 部署 web app:
kubectl apply -f todo-list/web/
# 获取应用访问 url:
kubectl get svc todo-web -o
jsonpath='http://{.status.loadBalancer.ingress[0].*}:8081/new'
# 访问并添加新的待办项
# 切换到 read-only 模式, 使用数据库备用节点:
kubectl apply -f todo-list/web/update/todo-web-readonly.yaml
# 刷新应用—现在/new的页面只读;
# 访问 /list 你将看到原始的数据
# 检查 Pod 0 中是否没有使用主服务器的客户端:
kubectl exec -it todo-db-0 -- sh -c "psql -U postgres -t -c 'SELECT
datname, query FROM pg_stat_activity WHERE datid > 0'"
# 检查 web 应用程序是否真的在使用 Pod 1 中的备用:
kubectl exec -it todo-db-1 -- sh -c "psql -U postgres -t -c 'SELECT
datname, query FROM pg_stat_activity WHERE datid > 0'"
您可以在图 8.11 中看到我的输出,其中有一些小屏幕截图,显示应用程序以只读模式运行,但仍然可以访问所有数据。

Postgres 作为 SQL 数据库引擎存在于 1996 年,比 Kubernetes 早了将近 25 年。使用 StatefulSet,您可以为适合 Postgres 和其他类似的集群应用程序的应用程序环境建模,从而在容器的动态世界中提供稳定的网络、存储和初始化。
8.4 使用 Jobs 和 CronJobs 运行维护任务
数据密集型应用程序需要复制数据,并将存储与计算对齐,它们通常还需要一些独立的存储层。数据备份和协调非常适合另一种类型的 Pod 控制器:Job。Kubernetes Job 是用 Pod Spec 定义的,它们将 Pod 作为批处理作业运行,确保它运行到完成。
Jobs 不仅仅适用于有状态应用;它们是为任何批处理问题提供标准的好方法,您可以将所有调度、监视和重试逻辑移交给集群。你可以在 Pod 中为 Job 运行任何容器镜像,但它应该启动一个结束的进程;否则,您的作业将永远运行。清单 8.5 显示了以批处理模式运行 Pi 应用程序的 Job Spec。
清单8.5 pi-job.yaml,一个简单的计算Pi 的 Job
apiVersion: batch/v1
kind: Job # Job 是对象类型
metadata:
name: pi-job
spec:
template:
spec: # 标准的 Pod spec
containers:
- name: pi # 容器将运行并退出.
image: kiamol/ch05-pi
command: ["dotnet", "Pi.Web.dll", "-m", "console", "-dp", "50"]
restartPolicy: Never # 容器若失败,将替换 Pod.
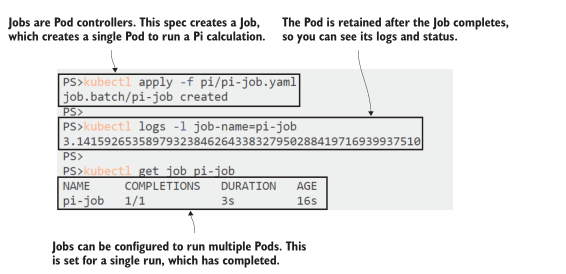
Job template 包含一个标准 Pod spec,并添加了一个必需的 restartPolicy 字段。该字段控制 Job 在响应失败时的行为。如果运行失败,您可以选择让 Kubernetes 用一个新容器重新启动同一个Pod,或者总是在不同的节点上创建一个替换Pod。在 Pod 成功完成的正常作业运行中,作业和 Pod 将被保留,因此容器日志可用。
现在就试试 运行清单 8.5 中的Pi Job,并检查 Pod 的输出
# 部署 Job:
kubectl apply -f pi/pi-job.yaml
# 检查 Pod 日志:
kubectl logs -l job-name=pi-job
# 检查 Job 状态:
kubectl get job pi-job
Jobs 将他们自己的标签添加到他们创建的 Pods 中。始终添加作业名称标签,因此您可以从作业导航到 Pods。图 8.12 中的输出显示 Job 已经成功完成了一次,计算结果可以在日志中找到。
有不同的选项来计算圆周率总是有用的,但这只是一个简单的例子。您可以使用 Pod spec 中的任何容器镜像,因此您可以使用 Job 运行任何类型的批处理。你可能有一组输入项,需要对它们做相同的工作;您可以为整个集合创建一个 Job,它为每个项目创建一个 Pod, Kubernetes 将工作分布到整个集群中。Job spec 支持以下两个可选字段:
- completions - 指定 Job 应该运行多少次。如果 Job 正在处理一个工作队列,那么应用程序容器需要了解如何获取下一个要处理的项。Job 本身只是确保它运行的 pod 数量等于所需的完成数量。
- parallelism - 指定在多个完成设置的作业中并行运行多少 pod。此设置允许您调整 Job 的运行速度,以平衡集群上的计算需求。
本章最后一个圆周率的例子:一个并行运行多个 pod 的新 Job spec,每个 pod 都将圆周率计算到一个随机的小数点后数位。该 spec 使用 init 容器生成要使用的小数点后数位,应用程序容器使用共享 EmptyDir 挂载读取输入。这是一种很好的方法,因为应用程序容器不需要修改就可以在并行环境中工作。你可以用一个 init 容器来扩展它,从队列中获取一个工作项,这样应用程序本身就不需要知道队列。
现在就试试 运行另一个使用并行性的 Pi Job,并显示来自相同 spec 的多个 pod 可以处理不同的工作负载
# 部署新 Job:
kubectl apply -f pi/pi-job-random.yaml
# 检查 Pod 状态:
kubectl get pods -l job-name=pi-job-random
# 检查 Job 状态:
kubectl get job pi-job-random
# 查询 Pod 输出日志:
kubectl logs -l job-name=pi-job-random
这个练习可能需要一段时间才能运行,这取决于您的硬件和它生成的小数位数。你会看到所有的 pod 都在并行运行,各自进行计算。最终输出的是三组圆周率,可能精确到小数点后几千位。我简化了结果,如图8.13所示。

Job 是你口袋里的好工具。它们非常适合任何计算密集型或IO密集型的情况,在这些情况下,您希望确保进程完成,但不介意何时完成。你甚至可以从你自己的应用程序中提交 job——一个运行在Kubernetes中的web应用程序可以访问Kubernetes API服务,它可以创建 job 来为用户运行任务。
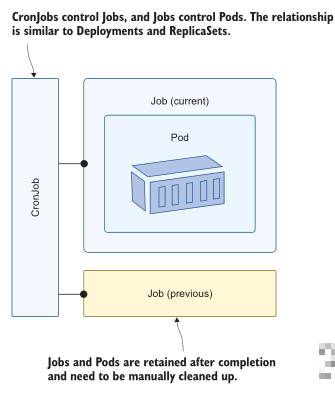
Jobs 的真正强大之处在于它们在集群上下文中运行,因此它们拥有所有可用的集群资源。回到 Postgres 的例子,我们可以在 Job 中运行一个数据库备份进程,它运行的 Pod 可以访问 statfulset 中的 Pods 或 pvc,这取决于它需要做什么。这就解决了这些数据密集型应用程序的培育方面的问题,但这些 job 需要定期运行,这就是 CronJob 发挥作用的地方。CronJob 是一个 Jo b控制器,它定期创建 Job。图 8.14 显示了工作流。
CronJob spec 包括一个 Job spec,所以你可以在 CronJob 中做任何你可以在 Job 中做的事情,包括并行运行多个补全。运行 Job 的计划使用 Linux Cron 格式,该格式允许您表达从简单的“每分钟”或“每天”计划到更复杂的“每个星期天早上4点和6点”例程的所有内容。清单 8.6 显示了运行数据库备份的部分 CronJob spec。
清单 8.6 todo-db-backup-cronjob.yaml, 用于数据库备份的 CronJob
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: todo-db-backup
spec:
schedule: "*/2 * * * *" # 每两分钟创建一个 Job
concurrencyPolicy: Forbid # 防止重叠,因此如果前一个作业正在运行,则不会创建新的作业
jobTemplate:
spec:
# job template...
完整 spec 使用 Postgres Docker 镜像,并使用命令运行 pg_dump 备份工具。Pod 从 StatefulSet 使用的相同 configmap 和 Secrets 中加载环境变量和密码,因此在配置文件中没有重复。它还使用自己的 PVC 作为存储位置来写入备份文件。
现在就试试 根据清单 8.6 中的 spec 创建一个 CronJob,每两分钟运行一次数据库备份作业
# 部署 CronJob 以及为备份文件的 PVC:
kubectl apply -f todo-list/db/backup/
# 等待 Job 运行—可以乘机喝杯茶:
sleep 150
# 检查 CronJob 状态:
kubectl get cronjob todo-db-backup
# 现在运行 sleep Pod 挂载备份 PVC:
kubectl apply -f sleep/sleep-with-db-backup-mount.yaml
# 检查 CronJob Pod 已创建备份:
kubectl exec deploy/sleep -- ls -l /backup
CronJob 设置为每两分钟运行一次,因此在这个练习中,您需要给它一些时间来启动它。CronJob 按照计划创建一个 Job, Job 创建一个 Pod, Pod 运行备份命令。Job 确保 Pod 成功完成。您可以通过在另一个 Pod 中挂载相同的 PVC 来确认备份文件已被写入。您可以在图 8.15 中看到它都正常工作。

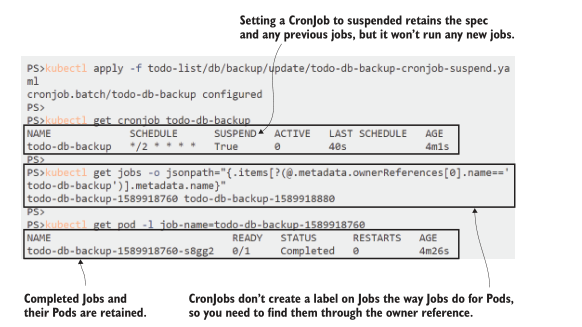
CronJobs 不会为 Pods 和 Jobs 执行自动清理。生存时间(TTL)控制器可以做到这一点,但这是一个 alpha 级功能,在许多 Kubernetes 平台上都无法使用。如果没有它,当您确定不再需要子对象时,您需要手动删除它们。您还可以将 CronJob移动到挂起状态,这意味着对象 spec 仍然存在于集群中,但直到 CronJob 再次激活它才会运行。
现在就试试 暂停 CronJob,这样它就不会一直创建备份 job,然后查看 CronJob 及其 job 的状态
# 更新CronJob,并设置为挂起:
kubectl apply -f todo-list/db/backup/update/todo-db-backup-cronjob-
suspend.yaml
# 检查 CronJob:
kubectl get cronjob todo-db-backup
# 找到 CronJob 拥有的 job:
kubectl get jobs -o jsonpath="{.items[?(@.metadata.ownerReferences[0]
.name=='todo-db-backup')].metadata.name}"
如果您研究对象层次结构,您会发现 CronJobs 不遵循标准控制器模型,没有标签选择器来标识它拥有的 job。您可以在 CronJob 的 Job template 中添加自己的标签,但如果不这样做,则需要标识所有者引用为 CronJob 的 Job,如图8.16所示。
当您开始更多地使用 Jobs 和 CronJobs 时,您将意识到 spec 的简单性掩盖了过程中的一些复杂性,并呈现了一些有趣的故障模式。Kubernetes 尽其所能确保批处理作业在您希望它们启动时启动,并运行到完成,这意味着您的容器需要具有弹性。完成一个 Job 可能意味着用一个新的容器重新启动 Pod,或者在一个新的节点上替换 Pod,对于 CronJobs,如果进程花费的时间超过调度间隔,则可能运行多个Pod。容器逻辑需要考虑所有这些场景。
现在你知道了如何在 Kubernetes 中运行数据量大的应用程序,使用 StatefulSets 来建模稳定的运行时环境并初始化应用程序,使用 CronJobs 来处理数据备份和其他常规维护工作。我们将在这一章的结尾思考这是否真的是个好主意。
8.5 为有状态应用程序选择平台
Kubernetes 最大的承诺是,它为你提供了一个单一的平台,可以在任何基础设施上运行你的所有应用。认为你可以建模所有的东西是非常吸引人的,使用kubectl命令部署它,并且知道它将以相同的方式在任何集群上运行,利用平台提供的所有扩展功能。但数据是宝贵的,通常是不可替代的,所以在决定将 Kubernetes 作为运行数据量大的应用程序的地方之前,你需要仔细考虑。
图 8.17 显示了我们在本章中构建的在 Kubernetes 中运行几乎是生产级 SQL 数据库的完整设置。只要看看这些活动的部分就行了.
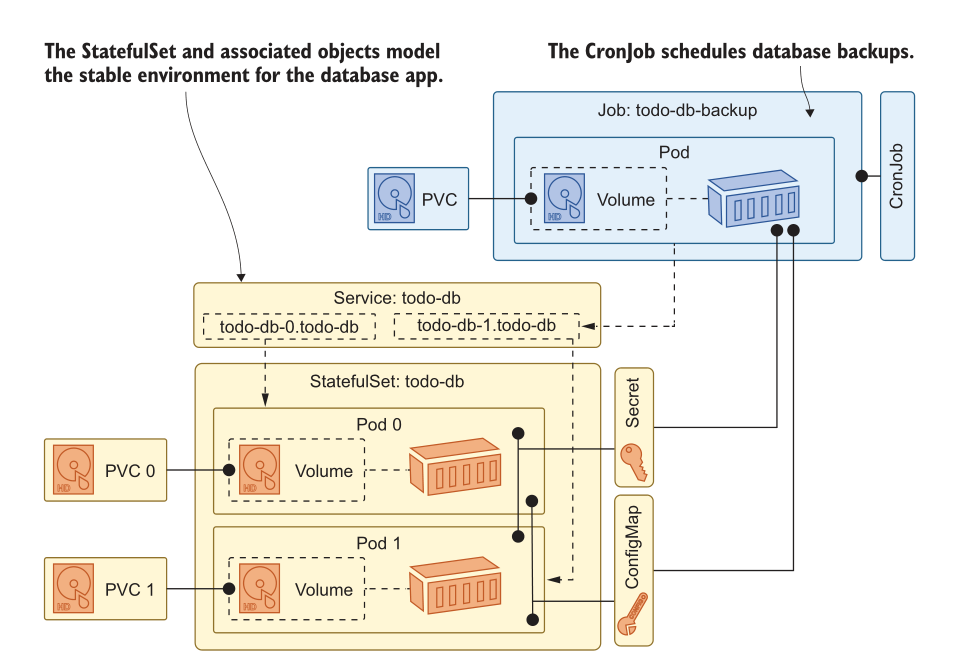
你真想搞定这些吗?仅用自己的数据大小测试这个设置需要花费多少时间:验证副本正在正确同步,验证备份可以恢复,运行混乱实验以确保以您期望的方式处理故障?
将其与云中的托管数据库进行比较。Azure、AWS和GCP都为Postgres、MySQL和SQL Server提供托管服务,以及他们自己的自定义云规模数据库。云提供商负责规模和高可用性,包括备份到云存储的功能和更高级的选项,如威胁检测。另一种架构只是使用 Kubernetes 进行计算,并插入托管云服务进行数据和通信。
哪个是更好的选择?我白天是个顾问,我知道唯一真实的答案是:“看情况而定。”如果您在云中运行,那么我认为您需要一个很好的理由不在生产环境中使用托管服务,因为在生产环境中数据至关重要。在非生产环境中,在 Kubernetes 中运行相同的服务通常是有意义的,因此您可以在开发和测试环境中运行容器化的数据库和消息队列,以降低成本和简化部署,并在生产环境中切换到托管版本。Kubernetes 让这样的交换非常简单,包括所有 Pod 和 Service 配置选项。
在数据中心,情况略有不同。如果您已经投资在自己的基础设施上运行 Kubernetes,那么您将承担大量的管理工作,因此最大限度地利用集群并将它们用于所有事情可能是有意义的。如果您选择这样做,Kubernetes 为您提供了将数据密集型应用程序迁移到集群的工具,并以所需的可用性和规模运行它们。只是不要低估实现这一目标的复杂性。
我们现在已经完成了 StatefulSets 和 job,因此可以在进入实验室之前进行清理。
现在就试试 所有顶级对象都被标记,因此我们可以使用级联删除删除所有对象
# 删除本章相关的对象:
kubectl delete all -l kiamol=ch08
# 删除 PVCs
kubectl delete pvc -l kiamol=ch08
8.6 实验室
你还剩多少午餐时间来实验室?你能从头开始建模一个 MySQL 数据库,有备份吗?可能不会,但别担心,这个实验室没有那么复杂。我们的目标只是给你一些使用 StatefulSet 和 PVC 的经验,所以我们将使用一个更简单的应用程序。你将在一个StatefulSet 中运行 Nginx web 服务,每个 Pod 将日志文件写入自己的 PVC,然后你将运行一个 Job,打印每个 Pod 的日志文件的大小。基本的部分都在那里,所以它是关于应用本章中的一些技巧。
- 起点是 ch08/lab/nginx 中的 Nginx Spec,它运行一个 Pod,将日志写入 EmptyDir 卷。
- Pod Spec 需要迁移到一个 StatefulSet 定义,它被配置为与三个 Pod 一起运行,并为每个 Pod 提供单独的存储。
- 当你有StatefulSet工作时,你应该能够调用你的服务,并看到正在写入 Pods 的日志文件。
- 在 disk-calc-job.yaml 文件中填写 Job Spec。添加卷挂载,这样它就可以从 Nginx Pods 中读取日志文件。
它并不像看起来那么糟糕,它会让你想到存储和 Jobs。我的解决方案在 GitHub 上,你可以在通常的地方检查:https://github.com/yyong-brs/learn-kubernetes/tree/master/kiamol/ch08/lab/README.md。